- Published on
The AI Platform That Wrote Its Own Benchmark Won
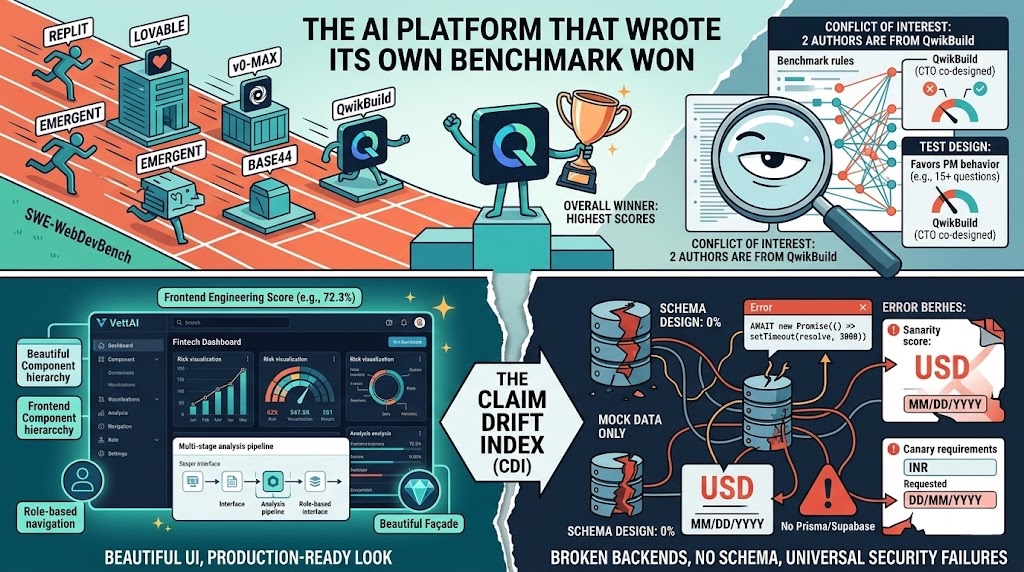
TL;DR: A new paper introduces SWE-WebDevBench, a 68-metric benchmark testing whether "vibe coding" platforms can actually function as complete software agencies. The findings are genuinely interesting: no platform exceeds 60% engineering quality, beautiful UIs mask broken backends, and security is universally terrible. But two of the three authors work for QwikBuild, which happens to score highest on most metrics. The benchmark is unusually transparent about this conflict, and the data is real. But the structural question of whether the test was designed to favor the test-maker deserves scrutiny.
What this paper does
A paper evaluates six major AI app-building platforms — Replit, Lovable, v0-Max, Emergent, Base44, and QwikBuild — as "virtual software agencies." Not just whether they can write code, but whether they can understand business requirements, make architecture decisions, handle modifications, and ship something production-ready.
The framing is ambitious. Most benchmarks test whether AI can fix a bug or write a function. This one asks: can it replace a software team?
The disclosure at the bottom of the abstract is worth noting up front: "Two authors are affiliated with QwikBuild, one of the six evaluated platforms."
What the benchmark actually does
The core idea is sound and, I think, genuinely novel. Instead of giving platforms a clean spec, they designed three prompts that test different failure modes:
P1: "The Founder's WhatsApp Ramble" — A stream-of-consciousness midnight text from a frustrated coaching institute founder. "Everything runs on WhatsApp groups and Google Sheets and I'm losing my mind." No mention of "CMS," "CRUD," or "RBAC." The platform has to infer a product from pain points. It also embeds Indian-specific conventions (JEE/NEET exam structure, DD/MM/YYYY dates, INR currency) and a deliberate contradiction about data visibility.
P2: An ultra-detailed enterprise RFP — A 10-state ticket lifecycle with SLA logic, and an explicitly marked contradiction the platform is supposed to flag.
P3: Maximum complexity AI-native — A fintech due diligence platform with Monte Carlo simulations, multi-stage AI pipelines, and credit systems requiring transactional integrity.
This prompt design is the paper's best contribution. Vague → detailed → complex tests fundamentally different capabilities. And the "canary requirements" — 80 culturally-specific details embedded throughout — are a useful way to distinguish real comprehension from template matching. A platform that generates a "standard SaaS app" will include login and dashboards but silently default to American date formats and USD instead of the requested DD/MM/YYYY and INR.
The findings that check out
The paper's strongest claim, that platforms produce polished frontends masking absent backends, is verifiable because they actually ship the generated codebases in the GitHub repo.
v0-Max's VettAI (the fintech prompt) tells the story. The frontend scores 72%. The paper describes it as having a well-structured component hierarchy with risk visualizations, a multi-stage analysis pipeline UI, and role-based navigation. It looks production-ready.
Then you look at the scores. Schema Design Score: 0%. There is no database. In the repo's evaluation files, the details are stark: no prisma/ directory, no supabase/, no ORM. All data comes from a static mock file. The repo's evaluation markdown confirms that the "Run Analysis" button calls await new Promise((resolve) => setTimeout(resolve, 3000)) and produces nothing. The Next.js config has ignoreBuildErrors: true. Zod is installed but never imported. The project name in package.json is literally "my-project".
A non-technical founder would look at this output and think they have a product. They would be wrong, and they'd have no way to know without reading the code, which is the whole point of vibe coding being that they don't.
The paper captures this gap with a metric called the Claim Drift Index, the delta between what the platform says it built versus what actually works. CDI ranges from 4% (trustworthy) to 35.7% (dangerously misleading). That means for high-CDI platforms, up to a third of claimed features don't work, and the user has no way to know.
Other findings that held up against the paper's data:
- Frontend is basically commoditized. Four platforms score within 6 points of each other on Frontend Engineering (68–74%). The differentiation is entirely in backend infrastructure, where scores span 0% to 49%.
- Security is universally bad. No platform exceeds 65% Security Score against a 90% target. Concurrency handling goes as low as 6%.
- Modification degrades quality. 16 of 19 metrics decline when you ask the platform to modify an existing app. Requirements that need to survive modifications degrade at 3× the rate of new ones.
The structural question
Here's where the conflict of interest needs to be examined directly.
Nilesh Trivedi, one of the paper's authors, is QwikBuild's co-founder and CTO according to the company's public profile. Vinayaka Jyothi, another author, also works there. That's two of three authors affiliated with a platform being evaluated.
QwikBuild scores highest on most metrics. Engineering Score: 54.5% vs. second-place Replit at 47.8%. Canary Retention Rate: 97.7% vs. next-best Emergent at 57%. Feature Completeness: 84% vs. 65%. Business Intent Fidelity: 3.7/4 vs. 3.0/4. It doesn't lead everywhere — Replit has a higher Frontend Engineering Score (74.3 vs. 68.0), v0-Max has a much higher SEO/Web Standards score (40.3 vs. 9.3), and Replit leads on Core Integration (70.0 vs. 67.3) — but the overall pattern is clear.
The benchmark website — webdevbench.com — is hosted on qwikbuild.site.
To be fair, the paper is remarkably transparent about this. The conflict of interest gets its own disclosure in the abstract, a dedicated subsection in limitations (§7.6), and they report QwikBuild's failures in detail: worst SEO/Web Standards across all platforms (9.3%), below-target concurrency (42%), lowest Code Hygiene among the top performers (52.8%), poor External Service Reliability (28.3% against an 80% target).
The third author, Siddhant Saxena from BaseThesis Labs (unaffiliated), designed the canary requirements and AMR prompts without prior knowledge of QwikBuild's architecture. And they release all prompts, rubrics, and scoring protocols for independent replication.
But the structural question remains: did the benchmark design itself inherently favor platforms that look like QwikBuild?
The evidence is suggestive:
PM behavior is a first-class evaluation dimension. The benchmark treats "asking questions before building" as a primary quality signal. QwikBuild has a dedicated PM agent that asks 15 questions across 6 rounds. Replit asks 0. This isn't a neutral measurement — it's an architectural choice about what quality means.
The AMR evaluation was completed only for QwikBuild. The modification-handling assessment, which the paper calls "fundamentally harder", was done exclusively for the authors' own platform, scored by the affiliated authors. They acknowledge this and call for independent replication, but the asymmetry is real.
The canary methodology rewards thorough requirement capture. Canary Retention Rate measures whether culturally-specific details survive the build. Platforms that ask more questions naturally capture more canaries. The paper doesn't make this causal claim directly, but the correlation is visible in the data.
The paper also stretches when it presents QwikBuild's zero-regression AMR results alongside all other platforms' ACR-only scores in Figure 12. The figure caption notes "cross-platform AMR evaluation pending," but the visual layout implies a comparison that doesn't yet exist.
Putting it together
The conflict of interest is real, but I don't think the paper is dishonest. The findings about frontend-backend decoupling, the specification bottleneck, and universal security failures are genuinely useful observations that hold up when you check the data. The canary methodology is clever. The prompt design is the best I've seen in any vibe coding evaluation.
What the paper actually demonstrates is something more subtle: the team that thinks hardest about what "software quality" means will design a benchmark that favors their own definition of quality. QwikBuild believes the PM phase matters most. So they built a benchmark that weighs the PM phase heavily. And they win on the PM phase. This isn't necessarily wrong — maybe the PM phase is the most important part — but it's also not a neutral finding.
The honest takeaway from this paper isn't "QwikBuild is best." It's:
No vibe coding platform is production-ready. Even the highest-scoring platform fails 17 of 22 metrics. Every generated app needs substantial human engineering before it ships.
Beautiful UIs are misleading. The gap between what these apps look like and what they actually do is the biggest risk for non-technical users.
The field needs benchmarks designed by people who don't sell platforms. This paper provides useful tools — the prompts, the canary methodology, the ACR/AMR distinction — but the definitive evaluation should come from independent researchers.
If you're evaluating these platforms for your business, budget 15–66 developer-hours of post-generation work. And don't trust the dashboard — check the Claim Drift Index.
The paper's most important contribution might be the infrastructure for someone else to run a fair evaluation. The prompts are good, the methodology is solid, the rubrics are public. Now we need someone without a horse in the race to use them.